英伟达双塔 AI 模型开源发布,文本生成速度提升 2.42 倍、画质保留 98.7%
2小时前2 阅读
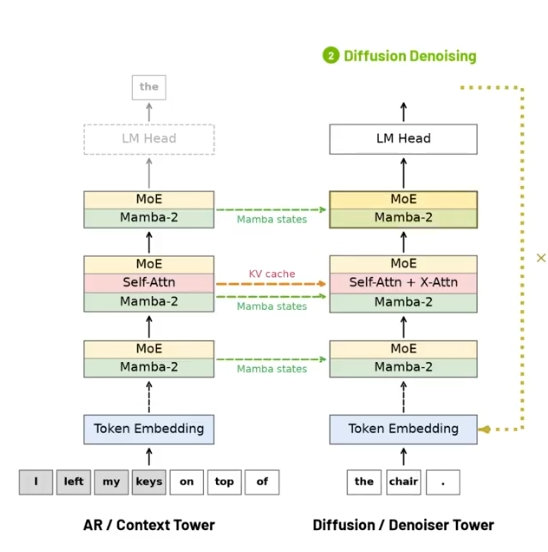
英伟达 7 月 2 日推出 Nemotron-Labs-TwoTower 离散扩散语言模型,旨在解决大模型逐一生成 Token 速度慢的痛点,相关权重已在 Huggingface 开源。模型基于现有 Nemotron 骨干网络改造,复用预训练权重,无需从零完整训练,大幅降低开发成本。 60B 双塔架构,分工并行提升生成效率 模型总参数量 60B,拆分为两座
英伟达 7 月 2 日推出 Nemotron-Labs-TwoTower 离散扩散语言模型,旨在解决大模型逐一生成 Token 速度慢的痛点,相关权重已在 Huggingface 开源。模型基于现有 Nemotron 骨干网络改造,复用预训练权重,无需从零完整训练,大幅降低开发成本。
60B 双塔架构,分工并行提升生成效率
模型总参数量 60B,拆分为两座 30B 独立神经网络协同工作,每塔激活 3B 参数,搭载 128 个可路由专家模块。上下文塔固定冻结,负责留存全文语义信息;去噪塔专门训练,依靠扩散机制并行生成文本,两塔通过交叉注意力互通数据。
传统模型逐 Token 串行输出,双塔架构可并行写入文本,大幅拉高推理吞吐量,兼顾速度与输出效果。多类基准测试数据显示,模型综合能力保留原版 98.7% 水准,文本生成吞吐速度直接提升 2.42 倍,仅代码、数学类任务小幅下滑。
开源落地,适配多场景推理部署
该模型采用英伟达专属开源协议开放权重,开发者可自由下载测试、商用部署。运行需搭配双张 H100 或 A100 80GB 显卡,单卡仅支持纯自回归模式,双塔完整推理需双卡协同。测试覆盖常识、数学、代码、阅读理解等多项任务,多数指标与原版基本持平,平衡了生成速度与内容质量。
要点速读
英伟达 7 月 2 日推出 Nemotron-Labs-TwoTower 离散扩散语言模型,旨在解决大模型逐一生成 To
- 英伟达 7 月 2 日推出 Nemotron-Labs-TwoTower 离散扩散语言模型,旨在解决大模型逐一生成 To
- 更多细节仍在持续更新中
- 更多细节仍在持续更新中